Date
Even though Google has attracted its fair share of controversy, I have to admit Google’s got to where they are because their tools are pretty good. Recently I stumbled across another of their tools I’m finding really useful: the Google Dataset Search.
The Dataset Search looks at metadata in thousands of repositories on the web, identifying those that are relevant to your search terms. For this to be possible, the repository must use a standard metadata schema — see here for more information about that. For my own project I’m compiling a large global dataset of plant foliar nitrogen measurements, so I’m using this very broad search term to cast a wide net1:
"foliar n" OR "foliar nitrogen" OR "leaf n" OR "leaf nitrogen" OR "foliar nutrient" OR "leaf nutrient"
The image below shows what this search returns. On the left, the sidebar lists the dataset titles and the repository/ies they are contained in. The main panel gives more information about a data set, as well as links to all the places in which it can be found. It’s possible to limit searches by criteria such as the data format (whether to include pdf files that are found in ResearchGate, for example), and whether the data are free to use.
Image
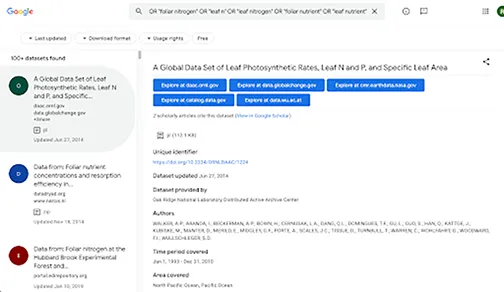
So this tool is potentially very helpful indeed, but there are a couple of things that mean it’s not quite as useful as it could be. I’ll go through these in a second, but I should first note that these issues are particular to the kind of search I’m doing, where I want a comprehensive list of available datasets. If you’re just looking for that one thing you’re kind of curious about, you’re probably fine.
First, I haven’t found a good way of repeating a search and determining whether I’m getting the same results each time. Take my long foliar N search term above, for example. This returns “100+” results; the search doesn’t give the exact number. I think there are actually about 400-500 results, and with that many to sift through, I’m definitely going to need to do the search more than once. However, there is no API and no way of saving the results, so I can’t readily tell whether anything has been added or removed in between searches2. This is not consistent with reproducible research!
Second, there’s no list of which databases are searched. That is, there could be a big, relevant repository out there that doesn’t use the standard metadata schema and therefore doesn’t show up in the search results. That’s not the end of the world, though; I’ve just made a list of the repositories that do appear (datadryad.org, daac.ornl.gov, etc; see the sidebar of the image), and I’ll run the list past my collaborators who can probably let me know if there are obvious gaps.
If you’re familiar with the Dataset Search and have solutions or workarounds for these problems, please drop a line to SESYNC cyberhelp. Otherwise, if you’re looking for data to help you figure out, oh I don’t know, whether there’s a spike in births 9 months after everyone’s been “sheltering in place,” maybe give the Google Dataset Search a try.
- You could also just search for “dogs”. That’s one of their top searches. Apparently. ↩
- Kelly H. cleverly suggested saving and parsing the source html. Unfortunately it appears to be generated on-the-fly as you scroll down the results, so I’ve only been able to make that work for searches that return <100 results. ↩
Share